
How human-reviewed machine-readable transcripts supercharge audio data
Kensho's Machine-Readable Human-Reviewed transcripts pair AI efficiency with human verification to deliver audio data that's simultaneously machine-ready and analyst-trusted.

There’s a wealth of information in speech recording data that typically cannot be found in textual data. From the more dynamic and casual nature of real-time speech to a speaker’s sentiments on different topics, speech recording data offers distinctive and invaluable vectors of information separate from their textual counterparts.
However, generating a 100% accurate transcription of audio and its rich features into a machine-readable format remains a challenge. While ASR (automatic speech recognition) and related models have made leaps and bounds in the past decades, factors such as audio quality, new or technical terms not existent in the model’s training data corpus, and regional accents and language barriers remain common struggles to even state-of-the-art models.
On the other hand, human transcription services, while generally capable of being more accurate than ASR, many times struggle to unpack the breadth of additional data in audio recordings (word-level timestamps, entity highlights, topic classification, sentiment analysis, etc.) into a format readily digestible by modern systems due to the tedious nature of the task.
Enter machine-readable human-reviewed (MRHR) transcripts
Machine-Readable Human-Reviewed transcripts combine the best of both worlds, merging modern technological capabilities with human reassurance to produce a transcription that is:
Machine-Readable: Delivered in a JSON or other data interchange format containing the structured annotation of the transcript with data from the word-level timestamps to advanced NLP analytics.
Human-Reviewed: Crafted with a human in the loop to fill in any mistakes common in AI-generated ones, such as unfamiliar words or sentences that require further research/context.
Having both these characteristics poses several benefits this article will cover that enable the consumers of transcript and the advancement of ASR as a whole.
Audio data enrichment (Search and analysis)
The explosion of audio data from experts and reputable sources in the past decade has reshaped the way we glean insights. However, simply listening and taking notes of recordings is no longer sufficient. What is now essential for a holistic understanding of relevant recordings on a topic is intelligently labeled transcriptions.
The shifting paradigm of audio analysis
Imagine you are an analyst tasked with covering and making investment decisions on Company A. In today’s audio-rich environment, relevant audio data is dispersed across a myriad of sources.
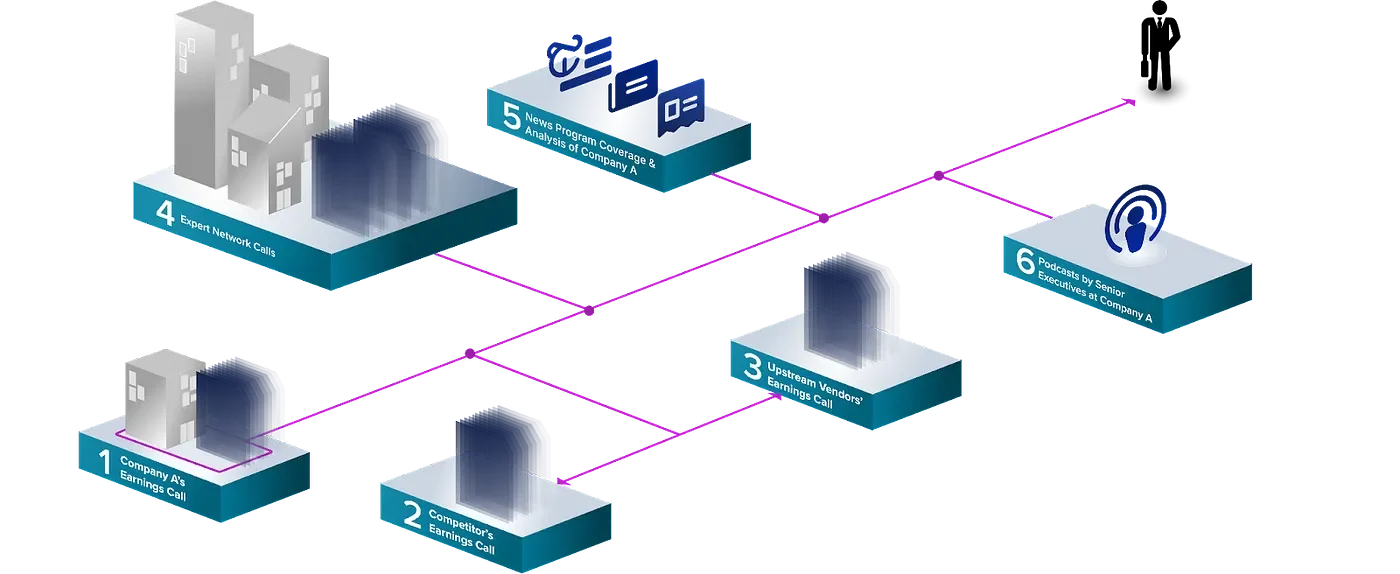
Company A’s Earnings Calls: A starting point for understanding the company’s own perspective and performance.
Company A’s Competitors’ Earnings Calls: Analyzing competitors’ perspectives provides a comparative benchmark and reveals industry dynamics.
Company A’s Upstream Vendors’ Earnings Calls: Exploring the supply chain from the source offers insights into potential risks and dependencies.
Expert Calls: Gaining insights from industry veterans can provide a nuanced understanding of industry-specific trends and challenges.
News Program Coverage and Analysis: Media coverage contributes to public perception of a company, reveal broader market sentiments, and can provide additional analysis on company specifics.
Podcasts by Senior Executives at Company A: Insights from executives’ discussions in a more informal setting may provide additional perspectives.
It would be a tedious task to keep track of, listen through, and digest all these audio sources for a single company. Machine-Readable Human-Reviewed Transcripts remedy this by offering searchability, analytic efficiency, and reliability when dealing with audio data.
Searchability
In their most basic form, machine-readable transcripts have not only the ASR output, but also embedded timestamps at the occurrence of each word. If you are only interested in what Company A’s competitors have to say about Company A, machine-readability combined with entity recognition allows you to both read that portion of the transcript and navigate to the exact time in the audio where Company A is mentioned. MRHR Transcripts also offer possibilities such as checking podcasts and news stories for mentions of a company.
Analytic efficiency
Beyond searching within a transcript for topics you may be interested in, it is useful to aggregate an opinion across multiple audio sources. While this may be an ambiguous task by just listening, with MRHR transcripts, you can gather data across multiple transcripts such as time spent talking about different topics, sentiment on those topics, and other key themes and patterns.
Reliability
We cannot forget that underpinning both searchability and analytic efficiency is the base reliability of the transcript. When reading transcripts to make decisions in finance, there are potentially millions (if not more!) dollars at stake. It is of the utmost importance that each word is transcribed correctly. Human review adds insurance that “million” isn’t transcribed as “billion”, “compliments” isn’t transcribed as “complements”, etc.
Training data creation and model enhancement
In addition to uncovering insights, MRHR transcripts are an integral part of enhancing our still-far-from-perfect ASR models.
MRHR transcript and audio combinations provide foundational ground truth for training ASR models. The accuracy of these transcriptions is paramount during training, ensuring that the model learns to understand and transcribe speech correctly. Transcribers bring an invaluable ability to understand and transcribe various accents, dialects, and speaking styles. Diverse human input ensures that the ASR system is equipped to handle the linguistic variability present in real-world scenarios.
Thoughtful machine-readable delivery also plays a pivotal role for scaling and building robust models capable of handling a wide range of speech patterns. Automation and standardization in machine-readable data formats streamline data processing. This efficiency allows for seamless preprocessing, augmentation, and organization of the data, optimizing the training pipeline and enhancing its capabilities.
Where you can get MRHR transcripts

At Kensho, we combine professionally trained transcribers specializing in business and finance language with a thoughtfully developed transcription platform, models trained to recognize business and finance language, and other AI-techniques to create Machine Readable Human Reviewed Transcripts in high quantities and quality.
Our humans-in-the-loop use Scribe, a platform built for producing machine-readable transcripts embedded with AI annotations, to transcribe business and finance calls. Scribe is the go-to tool for S&P Global for earnings calls and several large expert network firms for transcribing investment critical calls.
If you are looking for a scalable, efficient, and reliable way to transcribe audio data into a machine-readable human-reviewed format, find out more at https://scribe.kensho.com/.