
Distributed training with Kubernetes
Kensho's infrastructure team details how they used Kubernetes multi-node distributed training to tackle the cost and complexity of training large neural networks at scale.

By Rayshard Thompson and Dogacan Colak
Neural networks are more relevant than ever with the rise of GenAI, in particular large language models, and at Kensho we’ve been employing them in a wide range of applications. However, training these complex models can be computationally intensive and expensive. In collaboration with our ML Research team, Kensho’s infrastructure team tackled this challenge using a multi-node approach that could be easily integrated into our existing infrastructure. In this blog, we share the benefits and challenges of multi-node training, and how we leverage industry standard technologies such as PyTorch, NCCL, Kubernetes, and Airflow in our implementation.
Proof of concept

As neural networks grow in size and complexity, their memory requirements increase significantly which creates an upper bound on vertical scaling efforts. For example, assume a model requires 18 bytes of memory per parameter and we want to train it on a single GPU with a 16GB capacity. The GPU can only accommodate a model that is smaller than 900M parameters. In reality, many modern deep learning models have far more parameters, making it challenging to train them on a single GPU.
In the early stages, our ML researchers utilized interactive Jupyter Notebooks hosted on GPU-accelerated AWS EC2 instances. These notebooks were deployed using Kubernetes, facilitated by the NVIDIA k8s-device-plugin. While Jupyter notebooks were sufficient for small-scale experiments, the memory and quality-of-life limitations proved inadequate for longer and larger workloads. Even with the largest EC2 instances available, we needed a solution to horizontally scale across multiple nodes to increase memory capacity.
Initially, we sought support from the MosaicML team, and with their technical expertise and GenAI cloud training tooling, they assisted us in deploying their solutions on our infrastructure. In particular, our ML researchers benefited from their experience in determining optimal training hyper-parameters. However, as we hired our own experts and built more domain knowledge within our organization, we decided that having our own multi-node training implementation would be a more sustainable solution in the long run.
NCCL tests
Our first task in transitioning to multi-node training was ensuring seamless GPU communication across Kubernetes nodes using NCCL and NCCL tests. We deploy a StatefulSet, where each pod contains a single container that requests maximum resources from its node, and starts an SSH server to wait for connections. The container image has OpenMPI installed which is used by a separate launcher Job to launch the NCCL tests on the worker nodes. The launcher node discovers the workers through a host file containing the node hostnames established by the StatefulSet, and connects to them using a pre-configured password-less SSH connection. To view the full working code examples click here.
Enabling password-less SSH
# Install SSH client/server
RUN apt-get install -y -qq openssh-client openssh-server
# Enable passwordless SSH.
RUN mkdir -p $HOME/.ssh /run/sshd && \
# Remove existing host keys.
rm -f /etc/ssh/ssh_host* && \
# Regenerate SSH host keys.
ssh-keygen -A && \
# Use the host keys as client keys too.
cp /etc/ssh/ssh_host_rsa_key $HOME/.ssh/id_rsa && \
cp /etc/ssh/ssh_host_rsa_key.pub $HOME/.ssh/id_rsa.pub && \
# Remove the user field at the end with 'cut'.
# Add the public key to the authorized_keys file.
cat /etc/ssh/ssh_host_rsa_key.pub | cut -d' ' -f1,2 > $HOME/.ssh/authorized_keysWe encountered a few issues worth mentioning along the way:
NCCL creates shared memory segments in /dev/shm for inter-process communication within a node, so a dedicated ephemeral volume was mounted at dev/shm to provide extra disk space. See official troubleshooting documentation.
We use Linkerd as a Kubernetes service mesh which interferes with NCCL communication so we had to disable it on relevant nodes. If you use a different service mesh, you might encounter similar networking issues.
Pod template for StatefulSet
metadata:
annotations:
# Disable service mesh as it might interfere with networking.
linkerd.io/inject: disabled
spec:
containers:
- name: multinode
image: your-image-name # Image built from Dockerfile.
args:
- /usr/sbin/sshd
- -D # sshd won't daemonize.
ports:
- containerPort: 22
name: ssh
resources:
limits:
# Max number of GPUs in the host
nvidia.com/gpu: '4'
...
volumeMounts:
# Shared memory for comms within nodes.
- mountPath: /dev/shm
name: shm
volumes:
- emptyDir:
medium: Memory
sizeLimit: 13Gi
name: shmFor additional troubleshooting, setting NCCL_DEBUG to a more verbose level like INFO is recommended.
This method for GPU communication verification doubles as a viable training architecture for the popular framework DeepSpeed, involving a launcher Job and password-less SSH connection. The only changes are the command the launcher Job executes on the worker nodes and the need to install Deepspeed on the worker containers. But, we needed to devise another multi-node training architecture because some deep learning frameworks had a different launching process, such as the widely-used framework PyTorch, and its launcher torchrun.
PyTorch
Torchrun requires that each node individually executes the launcher command, which eliminates the need for the separate launcher Job and the password-less SSH setup. We can simply change the container entrypoint in the StatefulSet to the torchrun command. To view the full working code examples click here.
However, this approach introduces a new issue. Every time training is completed, the StatefulSet restarts the containers and launches training again. This is why, in our first prototype, we decided to switch to Indexed Jobs, to ensure that once training is over, pods are taken down. One trade-off, as discussed in this GitHub Issue, is that currently there is no way to mount the same Persistent Volume Claim (PVC) to all pods in an Indexed Job, which prompts further thinking in terms of storage solutions. However, as we will talk about in a later section, our Airflow implementation solves this problem.
Job manifest
apiVersion: batch/v1
kind: Job
metadata:
labels:
app: multinode
name: multinode
spec:
completionMode: Indexed
completions: 2 # Should match the number of nodes
parallelism: 2 # Should match the number of nodes
template:
spec:
containers:
- image: your-torchrun-image
name: multinode
args:
- sh
- -c
- torchrun --nproc_per_node $NGPUS --nnodes $NNODES --node_rank $JOB_COMPLETION_INDEX --master_addr $MASTER_ADDR --master_port $MASTER_PORT train.py
env:
# Node with rank 0 is chosen as the master node.
- name: MASTER_ADDR
value: multinode-0.multinode
- name: MASTER_PORT
value: '29500'
# Number of training nodes.
- name: NNODES
value: '2'
# Number of GPUs in the machine.
- name: NGPUS
value: '4'
ports:
- containerPort: 29500
name: nccl
resources:
limits:
# Request the max available amount of GPUs in your machine.
nvidia.com/gpu: '4'
volumeMounts:
# Mounting emptyDir as shared memory for communication within nodes.
- mountPath: /dev/shm
name: shm
restartPolicy: Never
# Required for pod-to-pod communication in Indexed-Jobs.
subdomain: multinode
volumes:
- emptyDir:
medium: Memory
sizeLimit: 13Gi
name: shmMoving to production
Training neural networks, no matter how exciting, comes with its fair share of challenges that need to be addressed for successful and efficient model development.
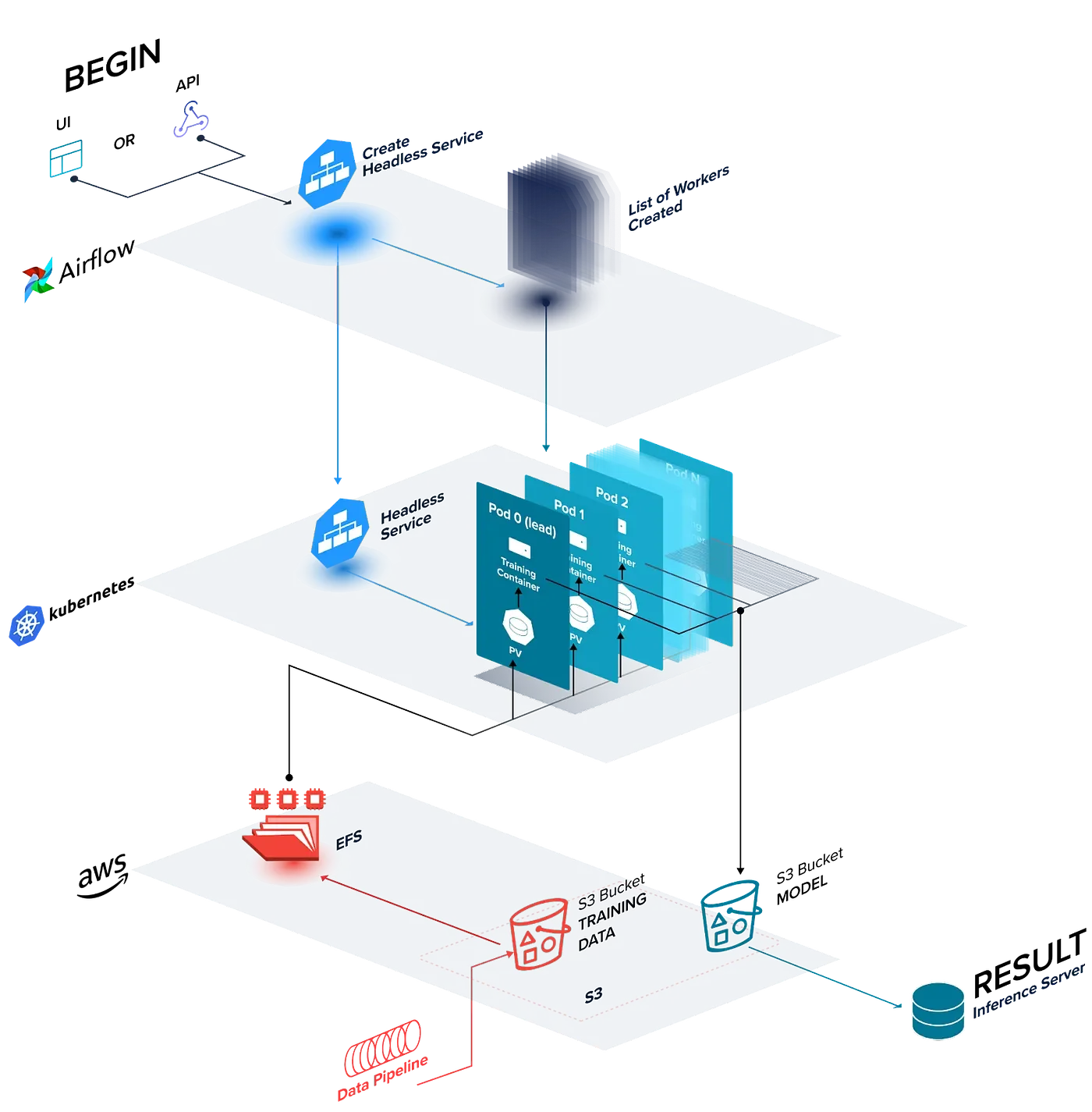
An architectural diagram of our distributed deep learning training framework, Kensho Quilt.
Orchestration improvements with Airflow
Kensho’s initial approach relied on built-in Kubernetes workload resources, but as we have outlined above, StatefulSets and Indexed Jobs come with their own downsides. We are transitioning our multi-node training infrastructure to Airflow, which marks a strategic shift for our operations. Similar to our original Kubernetes architecture, our Airflow Directed Acyclic Graph (DAG) implementation creates a headless Kubernetes service, along with a configurable pool of KubernetesPodOperator tasks, which allow Airflow to manage pod lifetimes instead of the Kubernetes control plane.
By leveraging a user-friendly tool already familiar to engineers within our organization, we streamline the learning curve and promote quicker adoption. Moreover, Airflow serves as a more adept resource controller, specifically tailored for orchestrating batch-oriented ML workloads. Additionally, Airflow’s rich ecosystem and extensibility will further cater to our evolving needs, cementing it as a practical choice for Kensho.
Storage

Since datasets can often be hundreds of gigabytes in size, how they are stored affects both training efficiency and cost in multi-node training implementations. At Kensho, we’ve faced various storage-related challenges, including the pros and cons of different network file systems, cloud storage devices provisioning issues, and significant time delays when downloading redundant datasets across machines. To mitigate these issues and ensure efficient resource utilization and developer productivity, it’s essential to carefully consider data loading pipelines and file system choices.
Our approach involves two cloud services: Amazon S3 and Amazon Elastic File System (EFS). We maintain a primary copy of the dataset on S3, which our data pipelines can easily populate, and our training nodes can stream to EFS.
This setup prioritizes minimizing costs and eliminates downloading the entire dataset at once. Training jobs streaming the data directly from S3 as needed is simply more effective. Streaming, in this context, means fetching data directly from S3 and buffering it in memory, then caching it on disk during training. If the dataset is sharded, each pod needs to stream only the relevant shards for its training.
During model training, a single EFS volume is mounted as a PVC to each pod. Within each run, to mitigate potential deadlocks arising from concurrent write operations, data from Amazon S3 is streamed into individual subdirectories for each pod. This ensures that multiple training runs, potentially using different datasets, are isolated. For instance, in the initial run, a directory labeled /run1 is created, with each pod writing to and reading from /run1/{j}, where j denotes the index of the respective pod. This methodology achieves several objectives:
Isolation of different training data for each training run.
Prevention of deadlocks during read/write operations by ensuring that each node within a run has isolated access to the training data.
Facilitation of distributing model checkpoints across nodes by storing them on S3.
Elimination of initial data download time by streaming the data instead.
However, it’s crucial that the streaming library can throttle downloads based on the memory limitations of the training nodes to prevent out-of-memory failures. Many widely used training libraries are actively working on implementing or improving streaming frameworks, such as MosaicML StreamingDataset, which we use at Kensho, or PyTorch Streaming DataLoader. While streaming isn’t always an available option, it’s worth considering when it is supported, especially as an alternative to local storage solutions like mounting persistent volumes.
Monitoring & metrics

The insights derived from tracking various metrics at both the training and GPU levels are instrumental in understanding model behavior and addressing potential challenges. A robust tool for monitoring training progress and experiment results is WandB (Weights & Biases), widely recognized as an industry standard. It compiles both training and system diagnostics such as loss, accuracy, CPU/GPU load, power consumption, and memory, as well as provides an interface for visualizing results and supporting collaborative work for model training.
At the GPU level, the NVIDIA Data Center GPU Manager (DCGM) Exporter can facilitate the extraction of GPU metrics, providing a granular view of the performance across nodes. Integrating DCGM Exporter with monitoring systems such as Prometheus and Grafana enhances the monitoring landscape, enabling a holistic analysis of the entire multi-node training setup.
In Kubernetes environments, NVIDIA offers the GPU Operator, a versatile tool that incorporates DCGM Exporter alongside other functionalities. However, at Kensho, we chose simply to deploy the DCGM Exporter as a DaemonSet on GPU machines.
Failure recovery

Training deep neural networks is a computationally intensive task that can take days, weeks, or even months to complete, particularly for large models. In case of a node failure during the training process, a graceful failure recovery mechanism is essential to eliminate the need for complete restarts of the training or constant supervision by an engineer. This mechanism should automatically resume training from the most recent model checkpoint, ensuring fault tolerance and avoiding nodes idling in a failed state. However, crafting a flawless solution to this challenge remains a formidable task for most organizations. Nonetheless, we have identified two distinct types of failures, each demanding a specific recovery approach.
Software-related failures:
These failures are typically transient in nature and manifest as error messages, often related to NCCL or CUDA. To address these issues, restarting the training run from the most recent checkpoint usually suffices.
Hardware failures (Node failures):
These failures are usually indicated by the training run hanging without any explicit error message, often resulting from problems with one or more nodes. Most commonly, these issues surface as XID errors originating from the GPU or the NVIDIA driver. Such errors are logged in the system’s kernel log and can be viewed using dmesg. NVIDIA has provided detailed debugging guidelines for various types of XID errors. In many cases, the solution involves rebooting the affected node. In more severe instances, cordoning the faulty node and replacing it becomes necessary.
Once a failure is identified, the appropriate recovery protocol can be executed, with the choice of automation or manual intervention depending on specific circumstances. This adaptive approach ensures that training can continue seamlessly even in the face of unexpected failures.
Networking

Enhanced network performance plays a pivotal role in optimizing the efficiency and cost-effectiveness of extended training processes. Most major cloud providers offer networking solutions tailored to applications demanding high levels of inter-node communication. Within this context, Kensho’s focus centers on AWS Elastic Fabric Adapter (EFA).
EFA functions as an elastic network adapter, augmenting conventional capabilities by enabling applications to communicate directly with their network interface hardware, bypassing the operating system. AWS optimizes EFA for NCCL which significantly enhances throughput (10x for 54 nodes, for example) and scalability for training models. Moreover, on supported instances, the integration of NVIDIA GPUDirect RDMA with EFA facilitates direct access to GPU memory, enabling direct GPU-to-GPU communication, substantially reducing latency in contrast to the conventional OS-level TCP/IP stack communication.
You can get started with EFA by following this guide. Here are some gotchas that we found useful:
Nodes must be confined to the same Availability Zone.
EFA Kubernetes device plugin is necessary to detect and advertise the EFA interfaces.
Kubernetes pods must declare the resource type vpc.amazonaws.com/efa in the request specification, akin to CPU and memory resources, in order to have access to their host’s EFA interfaces.
Cost

As models become more advanced, training expenses increase, requiring a careful assessment of cost-performance trade-offs. The main consideration is the choice between a fully on-premise setup, a fully cloud service setup, or a hybrid on-premise and cloud approach. On-premise setups involve significant upfront costs and may not be ideal for initial model development. Cloud providers offer flexibility with on-demand and pay-as-you-go services, but other factors such as machine types, storage devices, and networking infrastructure also influence cost. For example, AWS offers specialized GPU-optimized machines like P4d instances with EFA, which enhance node communication, possibly leading to reduced training time and overall cost. But for smaller training jobs, the benefits of using P4d instances might not justify the cost.
Conclusion
Kensho has embraced the challenges posed by training large language models head-on. Our journey into multi-node training, driven by the need to overcome memory limitations and enhance computational efficiency, has enabled advancements in our research endeavors. Leveraging industry-standard technologies, we’ve successfully implemented a robust and scalable infrastructure. As highlighted in this blog, our approach addresses critical aspects such as memory management, storage optimization, monitoring, failure recovery, networking, and cost considerations. As we navigate the ever-expanding horizons of deep learning, Kensho aims to continuously refine and innovate our methodologies to unlock new possibilities in the world of machine learning and artificial intelligence.