
Word Error Rate primer
A practical explainer on Word Error Rate: the most widely used metric for measuring and comparing the accuracy of automatic speech recognition systems.

What is Word Error Rate?
Word Error Rate (WER) is a commonly used metric to judge the accuracy of Automatic Speech Recognition (ASR) systems. It is the ratio of errors in the ASR’s transcription to the total number of words spoken.
Although there are other metrics to measure how well an ASR system is performing, WER is a relatively simple but actionable metric that allows us to compare ASR systems to one another, and evaluate an individual ASR system’s accuracy over time.
How is Word Error Rate calculated?
The WER is derived from the Levenshtein distance, named after the Soviet mathematician Vladimir Levenshtein. The Levenshtein distance is a string metric measuring the minimum number of edits needed to change one word into another.
Example:
The Levenshtein distance between “TARGET” and “MARKET” is 2, substituting the letters T and G for M and K

WER uses the Levenshtein distance at the word level instead of the character level.
In order to calculate the Word Error Rate, you need two variables: the text output of an ASR system, and the “ground truth” text — i.e. the exact words contained in the audio file.
WER is calculated by combining the total number of Substitutions (S), Deletions (D), and Insertions (I) in the ASR’s transcription, and dividing that by the total Number of Words (N) in the ground truth transcription.
WER Formula:
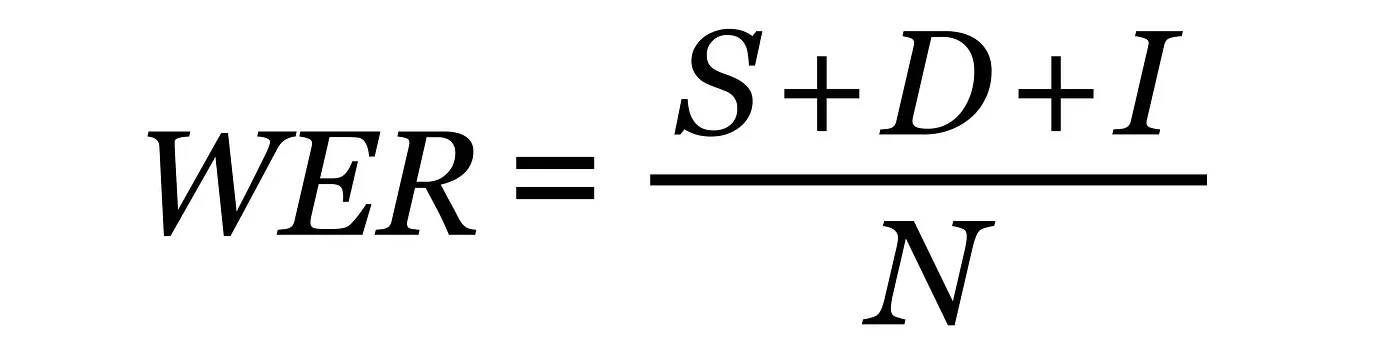
Substitutions are words your ASR transcribes in place of another word.

In this example, the incorrect word “Texas” was substituted for the correct word “tax”
Deletions happen when your ASR does not transcribe a word contained in the ground truth transcription.

In this example, the ASR system did not transcribe the word “sales” found in the ground truth transcription
Insertions consist of words the ASR system transcribes that are not found in the ground truth transcription.

In this example, the ASR system incorrectly transcribes the words “of charge” that are not found in the ground truth transcription
The number you get back after accounting for all substitutions, deletions, and insertions is your WER. Each error gets counted equally regardless of how consequential it is. The lower the WER, the more accurate the model!
WER calculation example:
In order to get a better understanding of how WER works, let’s take a look at an example:

Looking at the ASR’s transcription, we can see errors marked in red:
4 Substitutions:
’Additionally’/ ‘I’
‘our’ / ‘or’
‘and’ / ‘in’
‘growing’/ ‘glowing’
3 Deletions:
‘expect’
‘in’
‘oncology’
3 Insertions:
‘just’
‘cant’
‘lie’
In total, we have 10 error words out of 27 total words compared to the Ground Truth transcription, giving us a Word Error Rate of 37%
The importance of normalization
Now that we’ve covered what WER is and how it’s calculated, it’s important to take a step back and look at what needs to be done before calculating WER.
In order to calculate the most accurate WER, we need to establish guidelines around how to format the ASR and Ground Truth transcripts before the comparison begins. This process is called normalization.
Normalization consists of transforming text into a predefined standard. Each ASR model has their own way of formatting text and transcribing words and numbers. If we attempt to compare two models’ outputs without normalization, the WER will incorrectly penalize one or both models because of stylistic differences, rather than capturing true errors. This produces inaccurate and unreliable WER scores.
Some examples of what takes place during normalization:
Convert all characters to lower-case characters
Remove punctuation
Expand contractions (“isn’t” versus “is not”)
Standardize numbers (“eighty-three” versus “83”)
Remove filler and stop words (“um”, “basically”, “i think”, “the”, “a”, “than”)
To get a better understanding of how important normalization is when comparing ASR systems, let’s look at an example of what can happen if you attempt to compare two ASR systems without normalization first:

Running our WER analysis as-is, ASR 1 and ASR 2 both score WERs of 10.5%. However, if we look at the content of what each ASR system has produced, we notice that none of the information is actually incorrect. ASR 1 omitted a filler word, expanded contractions, and transcribed the number “thirteen” as text instead of a numeral. ASR 2 simply expanded contractions. These differences do not affect the meaning of the transcriptions.
Now, let’s normalize each output according to the five normalization examples listed above and compare again:

Running our WER analysis on the normalized text, both ASR systems score WERs of 0%, which is a more accurate comparison of how each ASR system performs.
Limitations of WER
As mentioned above, WER is a useful metric for comparing ASR systems and tracking an individual ASR system’s accuracy over time. That being said, WER does have its limitations.
1. WER doesn’t account for WHY errors are occuring
There are many variables that can affect an ASR model’s WER. Let’s take a look at some of the most common ones you’re likely to come across.
Rate of Speech
When someone talks quickly their words may bleed together into one long string, be pronounced incorrectly, or even dropped altogether. This makes it difficult for people to understand what is being said. The same is true for ASR models, which will be reflected in a model’s WER scores.
Accents
Everybody speaks with an accent. Where you grew up and how you learned to pronounce words from others in your community has shaped an accent that is unique to you. Sometimes these accents are subtle, and other times very obvious. Usually, with some effort, humans can understand someone with a strong accent without much prior preparation. For ASR models, however, this is considerably harder if they haven’t been trained on significant amounts of audio with speakers who have strong accents. They’re not able to adapt to drastically different pronunciations of words in the same way that humans are (usually) able to.
Background noise
To a human, differentiating background noise from a speaker’s voice is reasonably easy to do. If my friend is walking down a busy street in New York City, I’m able to distinguish their voice from the cars honking, passerby shouting, and countless other noises you’re bound to encounter in the Big Apple. To a machine, however, it can be difficult to separate my friend’s voice from all of the other noises.
Simultaneous speakers
I attended a town council meeting recently. When we got to the Q&A section of the meeting, one concerned citizen found themselves in a fierce debate with the moderator, each fighting for control of the conversation. While I was able to understand what both people were saying, a speech-to-text model will struggle with these overlapping conversations.
Whenever two or more speakers talk over one another, your model will find it difficult to prioritize which words to transcribe and when. This will lead to the model transcribing a jumbled string of sentences, and likely dropping many words as well.
Audio Quality
The quality of the audio input has a huge impact on the performance of your model. Audio from the race organizer yelling through a megaphone at the start of the New York Marathon is going to be much more challenging to understand than audio from a microphone in a soundproof studio. Depending on the audio input, your audio might experience distortions, echoing effects, dropped words, and other technical difficulties that will give your model trouble and drive up the WER.
Industry-Specific Jargon
The other day I was waiting in my doctor’s office and overheard a conversation about another patient. Two doctors were trying to identify the cause of the patient’s dyspnea. One doctor mentioned it appeared to be a case of trepopnea, as the dyspnea only occurred in one lateral decubitus position.
If you struggled to understand that last sentence, you’re not alone. Many industries such as medicine, law, and engineering all have unique jargon that is not commonly found in normal conversation — or in typical ASR model training datasets. Unless an ASR model is trained with audio from these specific industries, the model will struggle to accurately transcribe key terms.
2. WER doesn’t account for severity in types of errors
When dealing with speech-to-text transcription, some words are bound to be much more important to transcribe correctly than others. Incorrectly transcribing the name of your neighbor’s dog may not be catastrophic to your company, but incorrectly transcribing your company’s share price might.
Take a look at two examples from a recent meeting with investors:
Example 1:

The ASR model omitted only one word (not) from the transcription, but the importance of that omission is significant.
Example 2:

Similar to Example 1, the ASR model omitted a single word, “daily”, from the transcription. The omission in this case is rather inconsequential to the substance of the sentence.
As mentioned previously, incorrectly transcribing numbers like share prices can have a significant impact on a company. Let’s put this into perspective with two theoretical headlines from today’s paper:

Reading the latter headline is sure to send investors into a panic, and could have drastic implications for the future of our theoretical Company X. Okay, this may be a little dramatic, but it gets the point across — accurate transcription is important!
Conclusion
Word Error Rate is a powerful metric to gain an understanding of how your ASR model is performing. It can be used to compare your model to others (so long as normalization is part of the process) and track your model’s performance over time.
That being said, WER has its limitations and should not be the only metric you use. Experiment with a wide variety of audio, from town hall meetings to phone call conversations, to find weak points in your model’s performance.