
Kensho Classify: The solution to common text classification challenges
Kensho Classify identifies where specific concepts appear in text, with accuracy fine-tuned for the language of business and finance.

Text classification is widely used in many industries and often serves as a pillar for more complex workflows, from content discovery to investment strategies and decision making. Historically performed manually by domain experts, the process of tagging content was partially automated and performed by machine learning models. Most existing solutions have their own limitations and failure modes, as there are many challenges to overcome in order to build a general enough solution for the market.
The need for more than traditional methods
Despite being really cost effective, keyword search is often not a viable solution because of its lack of understanding of language, leading to significant amounts of false positives and false negatives. The need for a more expressive solution is clear.
However, from a traditional machine learning standpoint, building a reliable model can be expensive, requiring a significant amount of time and manual effort. Large amounts of labeled data are required to train models able to predict a given topic, and knowledge learned does not generalize to other categories. Furthermore, a complete model(s) retrain is required to incorporate new topics.
Time is money
In addition, the notion of a “relevant topic” can be ephemeral. Take the recent Silicon Valley Bank (SVB) banking crisis for example. For a few weeks, being able to identify risks for businesses related to the failure of SVB was crucial, but the same data is almost useless today. Stakeholders in the investment space needed to act quickly. They neither have the time to go through an extensive data collection and labeling process, nor want to dedicate a lot of effort for a few weeks of usefulness.

Why is text classification actually hard?
Several hurdles stand in the way of building a successful, robust and general solution. Firstly, the underlying models would have to adapt to a broad range of data distributions, from news articles to formal SEC filings, to earnings call transcripts.
Second, the definition of a topic can be very abstract and bear significantly different meanings across users. One user might be interested in sentiment analysis, while others may be interested in “general” topics such as passenger transportation, or relatively niche topics such as fuel cells.
Third, model calibration adds another layer of complexity, as whether a given text tackles a concept can be subject to interpretation. Should a model identify only the main subjects, or should it tag a topic as soon as it is briefly mentioned?
Last but not least, a great solution would fulfill use cases of users with different amounts of available resources, and more or less technical backgrounds.
Introducing Kensho Classify
To address some of these challenges, Kensho developed Classify, a solution enabling users to build classification models quickly, with minimal domain or machine learning expertise required. Kensho Classify understands text and goes beyond keyword search to facilitate lots of workflows. Ultimately, Kensho Classify provides paragraph-level annotations, with a confidence score for each topic identified.
Kensho Classify features three major operating modes in order to satisfy the requirements of users with different amounts of resources, data, or domain expertise.
First, the concept-set API annotates text documents on a collection of related concepts, identified by a unique keyword. These concept sets were designed by leveraging the financial domain knowledge of our parent company, S&P Global. As an example, only prompted with the GICS (Global Industry Classification Standard) concept set, Classify will identify any industry tackled within a document for the GICS Industry Classification.
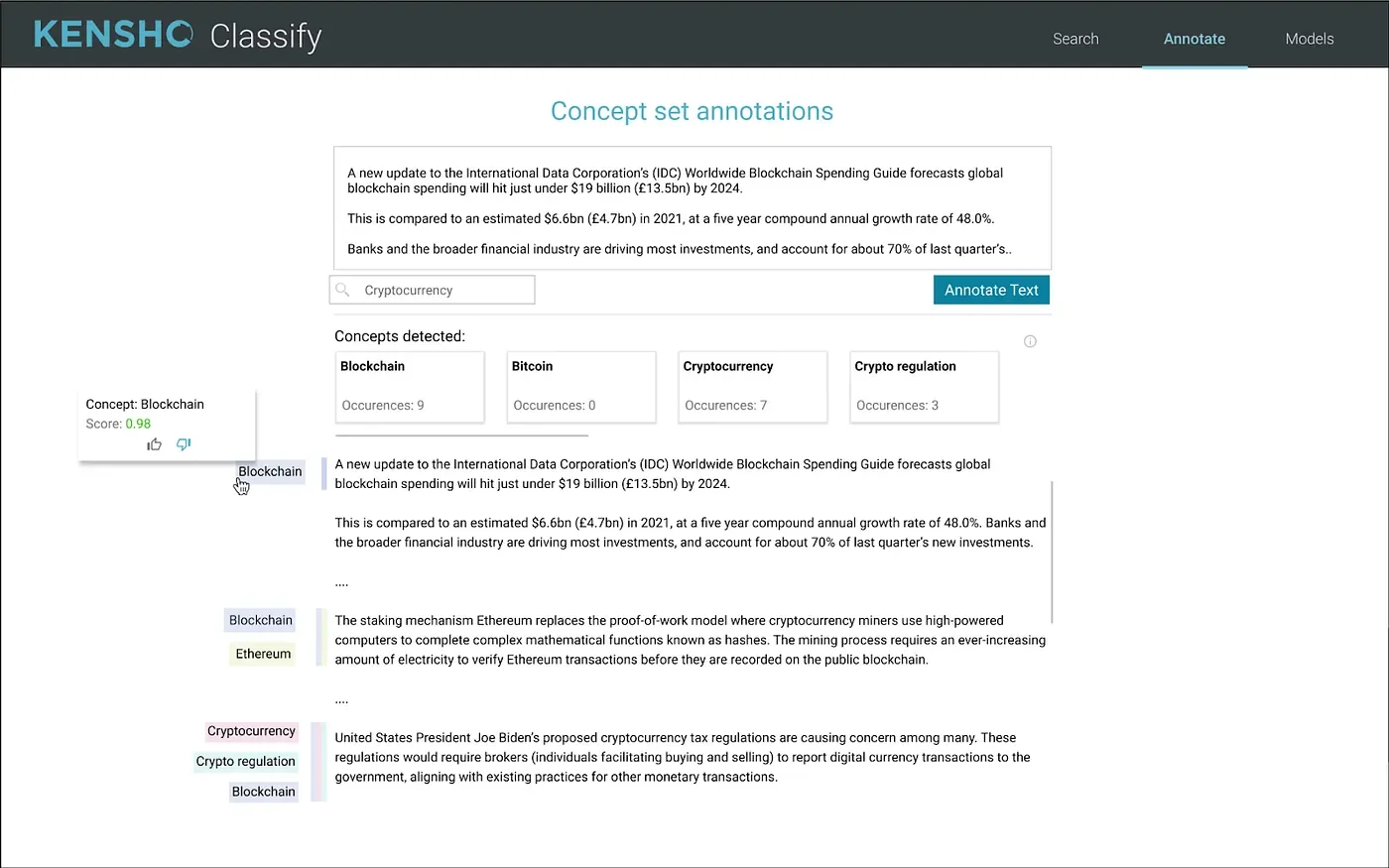
Classify annotations on a Cryptocurrency concept set
Zero-shot is the second operating mode and provides users with the ability to generate annotations on arbitrary topics, without having to provide any training data. Classify will leverage both language knowledge and understanding of text classification acquired during pre-training, and will adapt it to user-specified topics. For example, specifying electric vehicles as a concept is the only required effort to tag content relevant to electric vehicles.
Finally, the custom-concept API enables users interested in the highest classification performance to train their own models, on their own data and topics. For each topic of interest, Classify requires up to 15 positive and 15 negative text snippets (relevant and not relevant to the topic of interest) to train a model, specifically tuned for this use case. Classify will take advantage of the limited amount of data received to perform both input text domain adaptation, and topic domain adaptation.