
Databricks Data + AI Summit (DAIS) 2023 top themes
Kensho's top takeaways from DAIS 2023, where generative AI, LLM integration, and data governance dominated the conversation at Databricks' flagship conference.

In June, I had the chance to attend Databricks’ annual Data + AI Summit (DAIS) in San Francisco along with a team of my colleagues from S&P Global. In addition to showcasing our product and data offerings, we hosted a speaking session, Using Databricks to Power Insights and Visualizations on the S&P Global Marketplace.

Me (Tom, top left) and members of the team from S&P Global
Companies from all over the world were there for over 300 sessions and 20 keynote speakers. As a Product Manager at Kensho, S&P Global’s AI innovation hub, I attended this conference in an effort to learn more about the data/AI landscape — especially with the mainstream emergence of LLMs. The following are a few of my key takeaways from the conference, starting with the two biggest themes of the event:
Generative AI and LLMs: The emergence of ChatGPT has given the world a glimpse of how human-computer interaction may be redefined in the coming years. Across the industry, companies are taking note of the speedy advancements in LLMs and GenAI and are dedicating resources to apply or enable such technologies within organizations.
Excitement in the LLM space was further accentuated by the news of Databricks’ recent acquisition of MosaicML, a large-scale LLM training and deployment framework provider, for $1.3B.
Databricks Lakehouse Platform: Databricks combines what traditionally has been a data lake and a data warehouse. Having a centralized location for such data enables more robust data governance, cheaper data storage costs, and simpler schema definition. Many attending companies, including S&P Global, take advantage of such benefits in a multitude of ways such as easy client data sharing and fast/simple data visualization.

Data and AI Summit hosted at the Moscone Center in San Francisco. In the opening keynote, Databricks CEO Ali Ghodsi interviewed Microsoft CEO Satya Nadella
Takeaways on generative AI/LLMs
Picks and shovels for now
In its current form, technologies in the AI world are primarily focused on cloud provisioning, data/training pipelines, and feature stores. The picks and shovels. Many companies presenting and giving demos at DAIS were opinionated on where these tools should land on the value chain as we think about the future deployment of models.
Many no-code and low-code deployment methods were demonstrated, boasting end-to-end development of an LLM from data ingestion to model tuning to text generation.
Big or small? Proprietary or open source?
Enterprises care about cost. As LLMs leave research institutions and enter the industry, two major levers that affect cost and performance of enterprise-deployed models were repeatedly brought up — model size and open-source vs. proprietary.
Model size (Big or small?):
In the research world, the pattern in deep learning has been to create larger and larger models. These large models are typically good at generalized tasks.
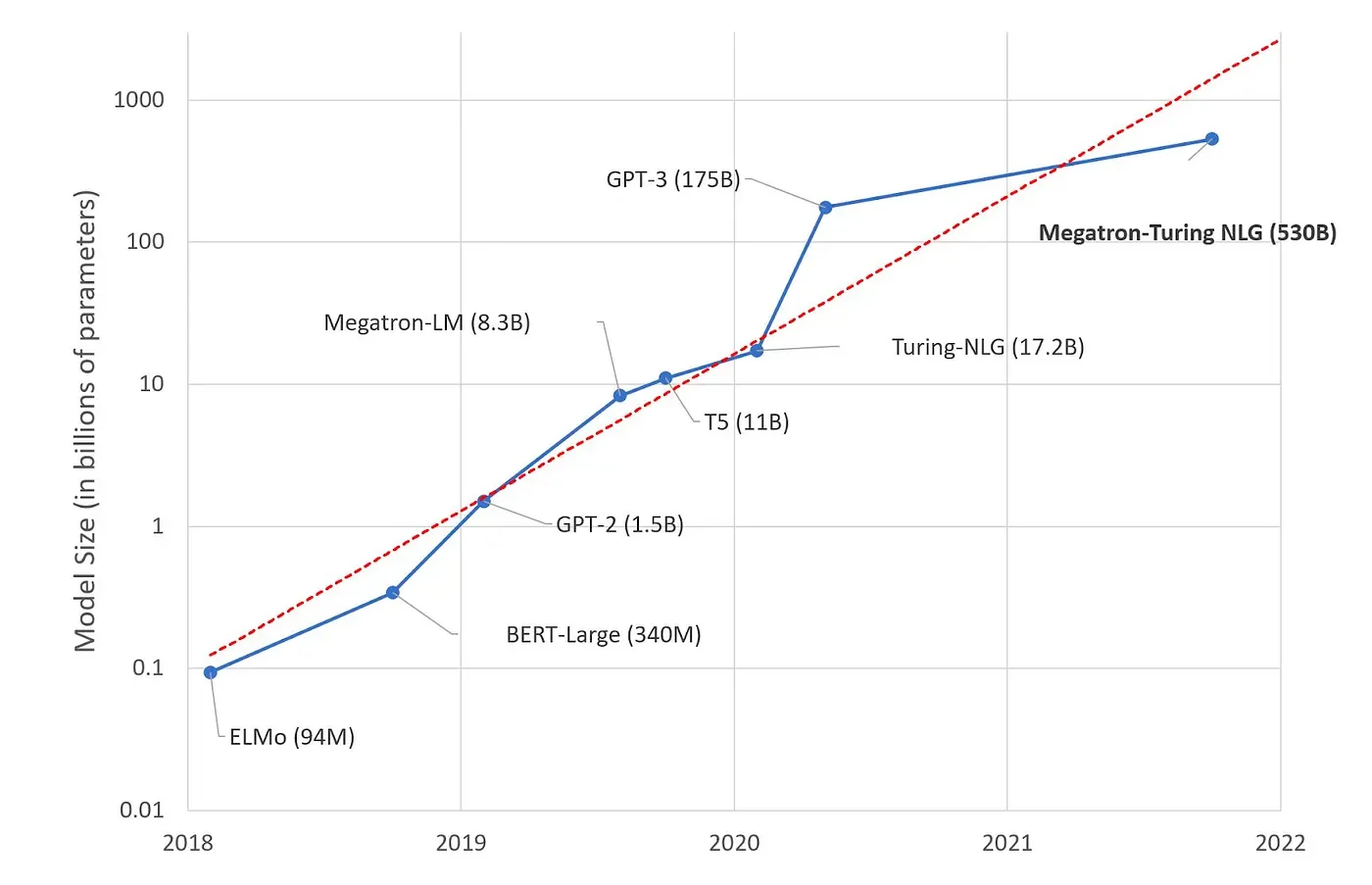
However, LLM developers must define a specific use case the AI must solve — and in this case generalizability may not be desired if the same user problem can be solved more cheaply with a specialized LLM. Many sessions at DAIS focused on building LLMs on a budget that fulfill domain-specific activities.
Kensho’s recent research and development of LLMs for the finance and business domains is testing the hypothesis that smaller, fine-tuned domain-specific models will outperform larger, more generalized ones at domain-specific tasks.
At the conference, other companies were able to train models that answered DAIS-related questions using Databricks’ open source 15k-dataset, scraped DAIS data, a synthetically generated Q&A dataset (using ChatGPT), and GPT2. While not state-of-the-art, those models adequately fulfilled their domain-specific purpose of answering any questions related to DAIS more cheaply and effectively than larger models.

Data and AI Summit hosted at the Moscone Center in San Francisco. In the opening keynote, Databricks CEO Ali Ghodsi interviewed Microsoft CEO Satya Nadella
Open source vs. proprietary:
Another key decision point companies adapting to the changing nature of the industry due to LLMs must make is whether to use an open-source model or proprietary model to solve customer problems.
On one hand proprietary models (such as OpenAI’s GPT-3) are extremely good at offering state-of-the-art results and a developer-friendly experience. However, they are restrictive when it comes to licensing, dubious when it comes to data privacy, and more expensive when it comes to cost.
On the other hand, open-source models are cheaper and give a lot of control to the developer. However, these models generally have much more intensive data and in-house expertise requirements.
Risks and regulations
As AI continues to advance, it has faced regulatory scrutiny as well. In the past year, several entities such as US states as well as national governing bodies have introduced proposed AI regulations.
Major concerns around LLM systems specifically lie in legal issues, ethical issues (bias and hallucinations), and social/environmental issues.
When looking at legality, data privacy and security are already topics making headlines, with companies such as JP Morgan altogether banning ChatGPT and other similar platforms from their internal networks. Finance is already one of the most heavily regulated industries, and tools used and built to support internal workflows must meet a high standard of reliability and trustworthiness.
Though not new, these problems pose higher stakes with the emergence of LLMs. While the principles of proper data anonymization, encryption, and access controls still hold, LLMs offer new ways that data security can be violated. For example, “prompt injections” via malicious code and misleading instructions may lead to the surfacing of confidential information.
Another example around IP protection considers possibilities that GenAI models may be trained on proprietary or copyrighted datasets. GenAI products are subject to licenses that will tell you how you can or can’t use them. Investigating the legal agreements to protect IP for models to determine if they are being used appropriately remains a big ticket challenge.
With regards to bias in models, big data does not always mean good data. Many times, large datasets contain toxic data, such as non-public information or false information, that you would not want to inform a decision-making process. For LLMs specifically, there is the unique problem of misinformation through hallucinations. Hallucinations are a phenomenon where the model generates outputs that are plausible sounding but are inaccurate or nonsensical. Hallucinations become dangerous when users start to increasingly rely on models in their workflows. This can also lead to further degradation of information quality.
It was exciting to see the transformative work being done in both Data and AI. As infrastructure is being built, the possibilities of using Data and AI in never-before-seen ways increases. As new use cases arise, companies must look to strike a balance between innovating and making progress on the one hand, and operating ethically and maintaining responsibility in an emerging landscape on the other.
Are you as excited about all of this as we are? We’re hiring! Check out our open positions and consider joining the Kensho team!