
Introducing PubTables-v2: Kensho’s new dataset empowering next-gen AI for table extraction
Kensho releases PubTables-v2: a first-of-its kind open-source dataset of 500,000+ fully annotated tables, purpose-built to train the next generation of document AI models.

The sheer volume of documents processed daily across finance, government, and research is staggering. Within these documents — annual reports, regulatory filings, scientific papers, and more — lies critical, structured data trapped in the form of tables. Table extraction, the process of accurately pulling this data out, is a foundational task in document AI.
Recently, a significant development in AI for documents has been the rapid adoption of vision-language models (VLMs). These models have the potential to understand documents more holistically, while also simplifying traditional multi-stage pipelines.
However, there is a gap. Standard benchmarks for evaluating the table extraction performance of these models were not designed to evaluate fully end-to-end. Typically, the tables in these benchmarks have been cropped from their source documents, rather than presented in their full page or document context. This simplifies the evaluation but side-steps some of the real-world challenges VLMs aim to solve.
To address this, we are releasing a first-of-its-kind large-scale dataset for end-to-end table extraction: PubTables-v2.
With PubTables-v2, we aim to empower the next generation of table extraction methods.
Some of the highlights:
It’s really big: PubTables-v2 contains over 500k tables fully annotated for end-to-end table extraction in a variety of document contexts.
It’s challenging: Like many real-world tables, the tables in PubTables-v2 are either very large or embedded in a large surrounding context.
It goes beyond the tables themselves: Tables within pages are connected to their surrounding captions and footers.
It’s novel: PubTables-v2 is the first dataset that annotates tables spanning multiple pages, a problem that has been all but ignored in the research literature.
It’s high-quality: Like its predecessor PubTables-1M, v2 uses multiple automated quality control steps to ensure correct annotations.
Rethinking table extraction benchmarking
One of the most challenging aspects of real-world table extraction arises from scale. Long tables and documents can stretch systems’ computational limits and their ability to maintain consistency across their entire output. However, these challenges are not well-represented in public AI benchmarks and model training datasets.
To address this, we needed to rethink the traditional approach to benchmarking table extraction systems. Traditionally, benchmarks decompose table extraction into two sub-problems: table detection, followed by table structure recognition. However, this biases AI solutions to adopt this practice. It is also an incomplete solution: what about tables that are split across multiple pages? This is a real-world problem that document AI research has almost entirely ignored.
Instead, we decided to reframe table extraction as a single end-to-end problem occurring within multiple different contexts. By context, we mean: what and how much document content surrounding the table is present as part of the table extraction input.
PubTables-v2 contains tables in three different contexts:
Cropped Tables: Tables are cropped from their source document and presented in isolation, effectively context-free. This corresponds to the traditional table structure recognition task.
Individual Pages: Tables are presented in the context of a single page. Each page contains one or more tables, and every table within a page is annotated.
Full Documents: Tables are situated within a complete (multi-page) document. For each document, all of its pages are included, and every table in the document is annotated.
Notably, PubTables-v2 is the first large-scale dataset with thousands of tables for multi-page table extraction.

PubTables-v2 is the first large-scale dataset with thousands of tables for advanced multi-page table extraction.
PubTables-v2 is the first large-scale dataset with thousands of tables for advanced multi-page table extraction.
While we do include cropped tables in our dataset, we restrict these only to very large tables spanning nearly the full length or width of a document page, which are much more challenging than the cropped tables in existing datasets.
Evaluating the state-of-the-art
VLMs hold the potential to address full end-to-end table extraction, but the computational complexity of current large VLMs is a disadvantage — as is their propensity to produce hallucinations.
A current trend in document AI research is to develop smaller VLMs specialized for document understanding and parsing tasks. With PubTables-v2, we set out to evaluate these for the first time on end-to-end full-page table extraction.
We also wanted to compare the performance of these existing models with an approach trained specifically on our dataset. For page-level table extraction, we chose to create a simple extension of the well-known Table Transformer (TATR): the Page-Object Table Transformer (POTATR).
POTATR is similar enough to TATR to serve as a strong baseline model, while adding features necessary to leverage the unique aspects of PubTables-v2, such as explicitly connecting tables to their captions and footers.
Standard evaluation metrics for table structure recognition (TSR) include Tree-Edit Distance Similarity (TEDS) and Grid Table Similarity (GriTS). However, these both assume one predicted table is being evaluated against one ground truth table. In our case, where a model receives a full page as input and can predict multiple tables, this assumption no longer holds. To address this, we developed a modified version of GriTS that considers all possible matches between two sets of ground truth and predicted tables and computes the best possible match score.
We evaluated POTATR versus four recent small specialized VLMs: SmolDocling, Qwen2.5-VL-3b, granite-vision-3.2–2b, and GraniteDocling. We measured performance using two variations of GriTS: GriTS-Top, which measures the structure of predicted tables only, and GriTS-Con, which considers the text content in addition to the structure. Our results are below.
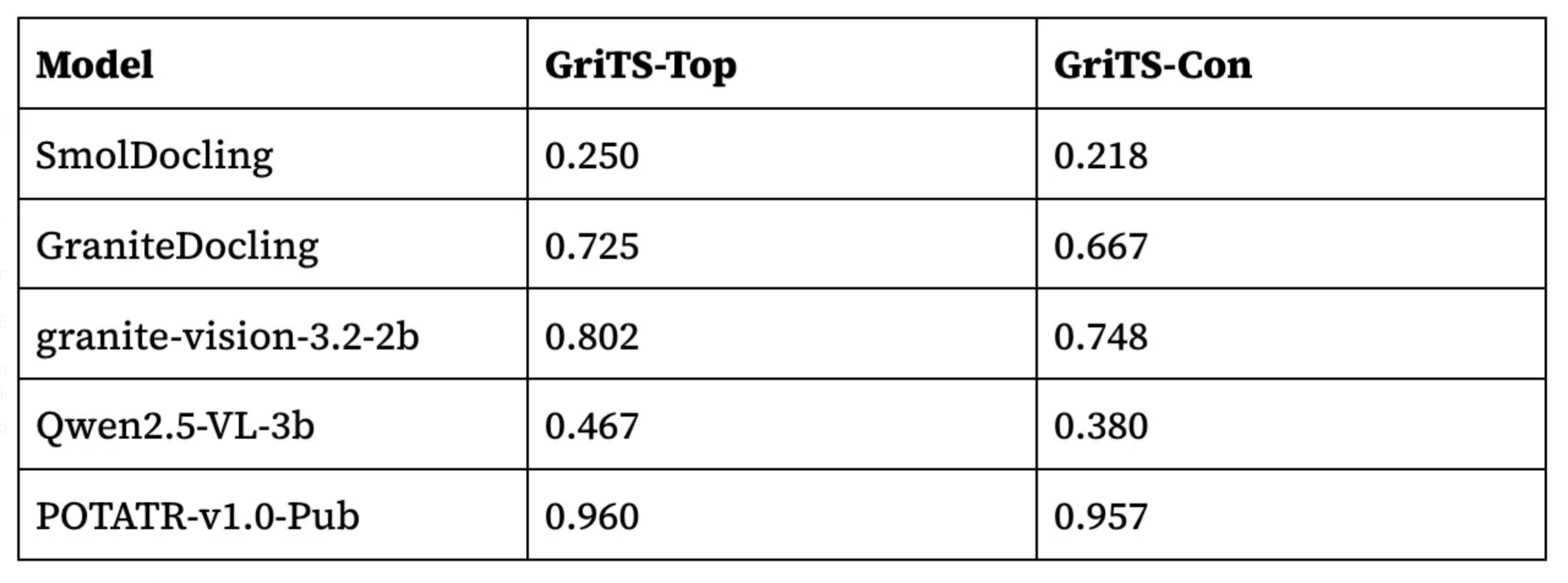
As expected, the non-VLM POTATR-v1.0-Pub model trained on PubTables-v2 performs very well, achieving a GriTS-Top score of 0.960. This establishes a reasonable baseline of performance for comparison with existing VLMs, which have not yet been trained specifically on PubTables-v2, but nevertheless aim to generalize across many domains.
Note: One additional key difference between POTATR and VLMs is that POTATR relies on a post-processing step that leverages text directly from the document, and does not perform its own optical character recognition (OCR). Errors in text recognition show up in the GriTS-Con metric, which we can see is noticeably lower compared to GriTS-Top for all VLMs, but not for POTATR. POTATR’s direct use of document text eliminates a source of error when accurate document text is already available. However, in documents that require OCR such as scanned documents, POTATR’s performance on the GriTS-Con metric would depend on the choice of OCR method.
Among the existing small VLMs, which as we noted are not trained on PubTables-v2, there is substantial variation in table structure recognition performance. The best performing model in this group achieves a GriTS-Top score of 0.802, much lower than the baseline score set by POTATR. Thus, the ability of these models to handle page-level table extraction in scientific articles has not yet been fully realized.
But these models are rapidly improving. We can likely expect to see continued performance improvements on this benchmark with models released in late 2025 and into 2026. As new models are released, we are eager to evaluate them on our benchmark and update our findings.
Another interesting observation is that among the VLMs evaluated, larger models are outperforming their smaller counterparts. Reducing the size of VLMs while maintaining performance is a key research direction to continue to follow in 2026.
Of course, these results only scratch the surface. For more details and current results, read our full paper here.
Special thanks to my co-authors Valerie Faucon-Morin, Max Sokolov, Libin Liang, Tayyibah Khanam, and Maury Courtland.
Download the open-source dataset
As models evolve, so must our datasets and benchmarks. We hope that PubTables-v2 is a big step forward for end-to-end evaluation and empowers the next generation of document AI approaches.
Interested in using the data yourself? It’s permissively-licensed and available for download here.
Looking to extract tables of your own? Try our product, Kensho Extract.