
Introducing NERD UI: The revolutionary tool for research and analysis
Kensho's new NERD UI surfaces the who, what, and where behind any document — delivering entity-level intelligence at your fingertips.
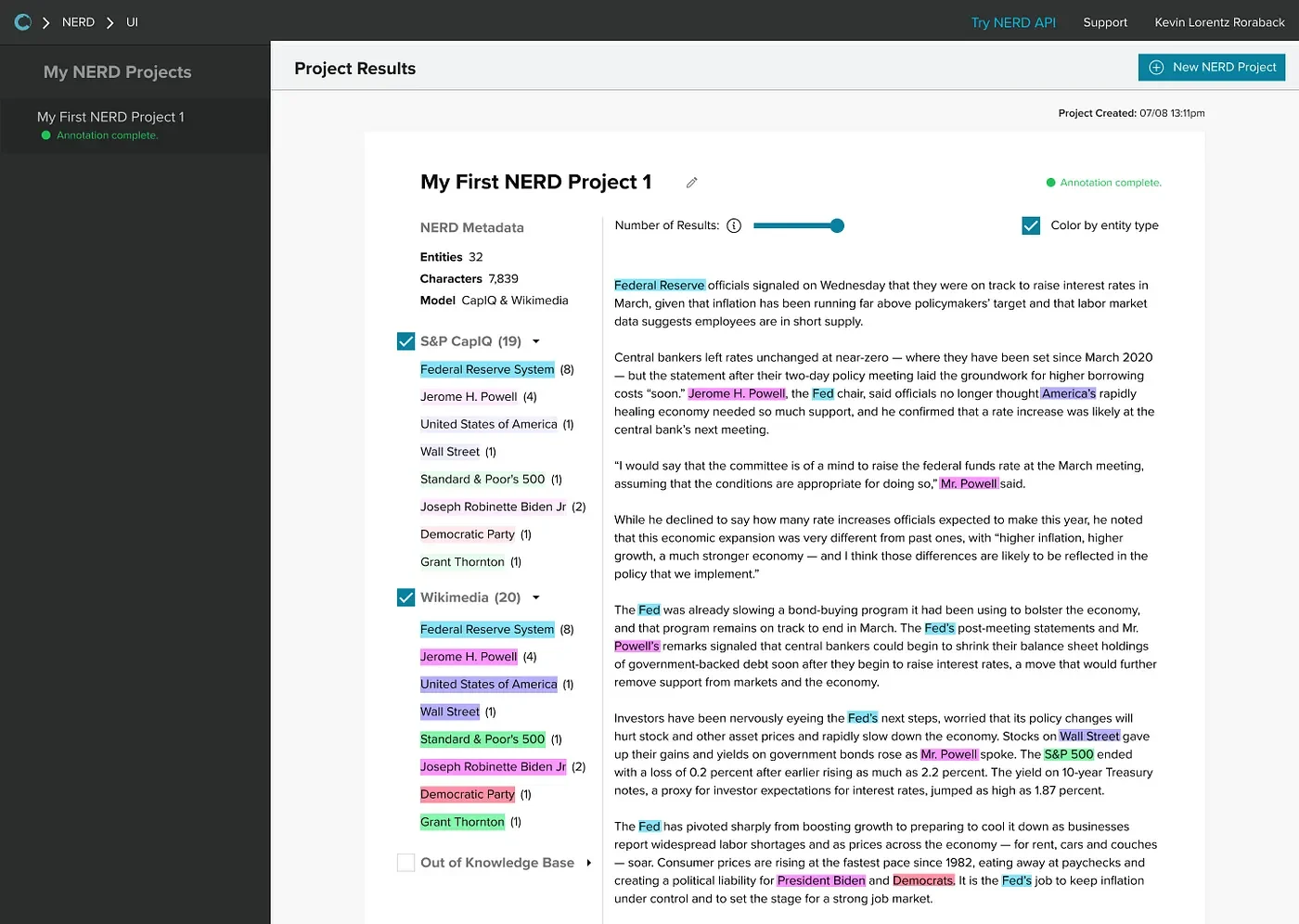
With today’s announcement, the NERD UI will now allow users to gain insight into the who, what and where of any document, making research and analysis easy. For any proper noun, NERD provides additional relevant information at the user’s fingertips.
What better way to jump into Q1 than with an announcement that dramatically makes one of our products easier to use? We’re ready for you, 2023!
Kensho NERD (Named Entity Recognition and Disambiguation) has added a fully featured user interface (UI) in addition to its already popular NERD API.
NERD is Kensho’s solution to identify and understand entities such as companies, people, places or events, unlocking the full potential of textual data. Trained on millions of business-related documents, NERD is a natural language processing solution optimized to extract and understand different types of entities in text documents using a context-aware model.
NERD consistently outperforms competitive solutions for entity recognition and disambiguation, with a 4–15% performance boost when compared to similar solutions in a recent benchmark study.
To date, NERD’s primary form factor has been an API, which allows users to work programmatically across hundreds, thousands or even millions of documents. But many of our users and prospects have voiced the desire for a solution that’s accessible by someone less technical within their organization, an easy-to-use interface that could be used in research and analysis workflows by knowledge workers such as lawyers, competitive intelligence analysts, management consultants or others.
You asked. We listened.
By putting relevant data and information on entities at your fingertips, NERD removes the cost of context switching. It allows users to focus on actually reading, understanding and extracting insight from content. NERD can handle any size document. Want to annotate an entire book? Go right ahead.
What makes NERD so effective is that it’s designed to link to two highly robust sources of structured data that combine for more than 100 million entities — S&P Global’s Capital IQ and Wikimedia — which exponentially increases the value of unstructured data. It gives users accurate background data on any entity directly connected to their text.
It is important to note that for users wanting to work with NERD at scale (i.e. thousands or millions of documents), the API is still best suited for their needs. NERD’s UI and API provide different ways to use NERD to its fullest potential.
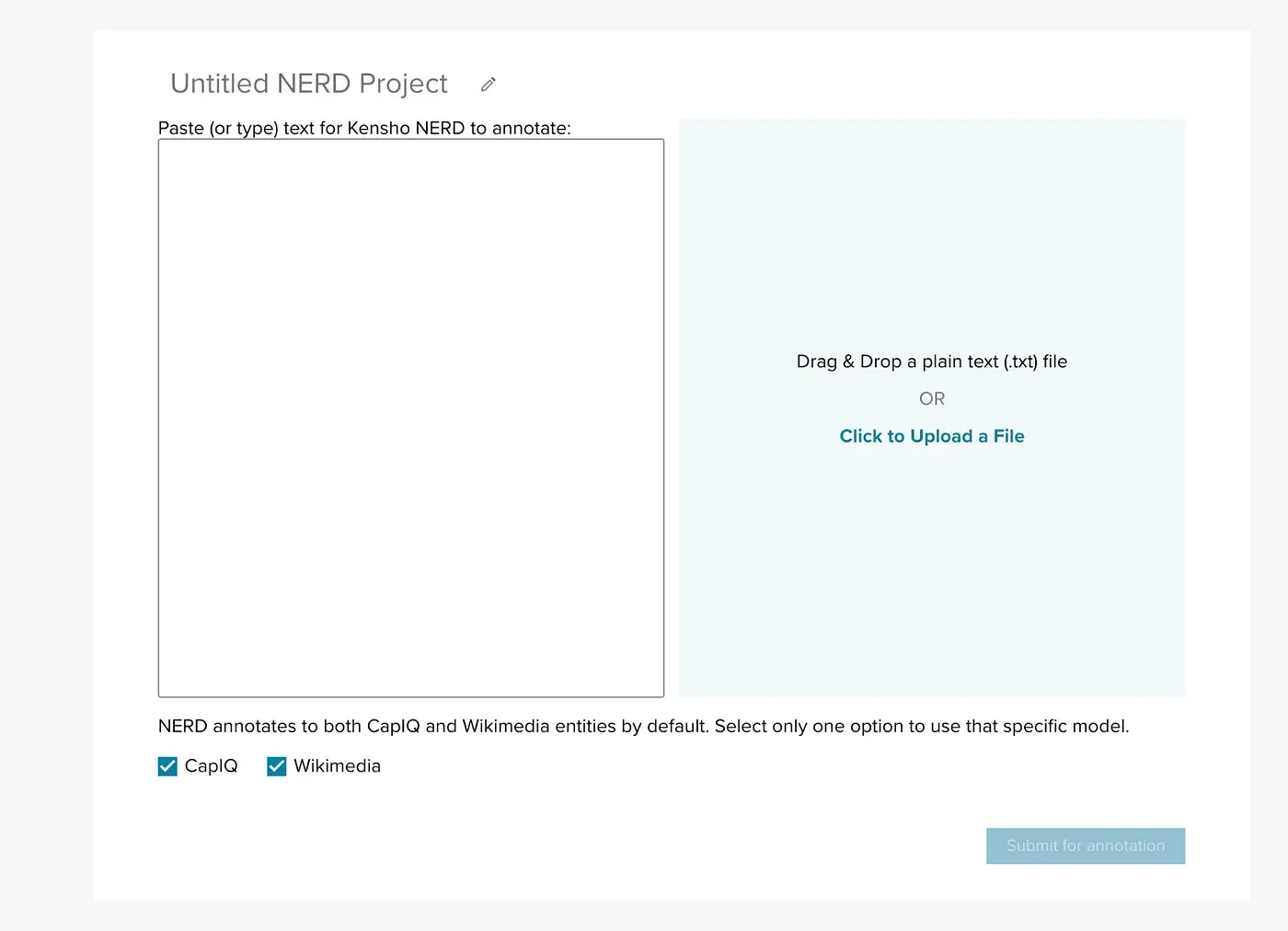
What’s next? Our roadmap for this year includes ways to upload new types of files (PDF, Google Documents and more), analytics across documents, batch processing multiple documents at once, integration with other NLP capabilities and more! Stay tuned!
The NERD team is excited to offer this powerful new tool to the market, and we look forward to seeing how it can help our users unlock new insights and make better decisions.