
Kensho industry use case: Entity & thematic tagging for document filtering and search
See how expert networks use Kensho NERD and Classify to automatically tag and surface insights across thousands of interview transcripts.

This blog is part of our series on how Kensho solutions can be used in various industries to unlock insights hidden in messy and unstructured data.
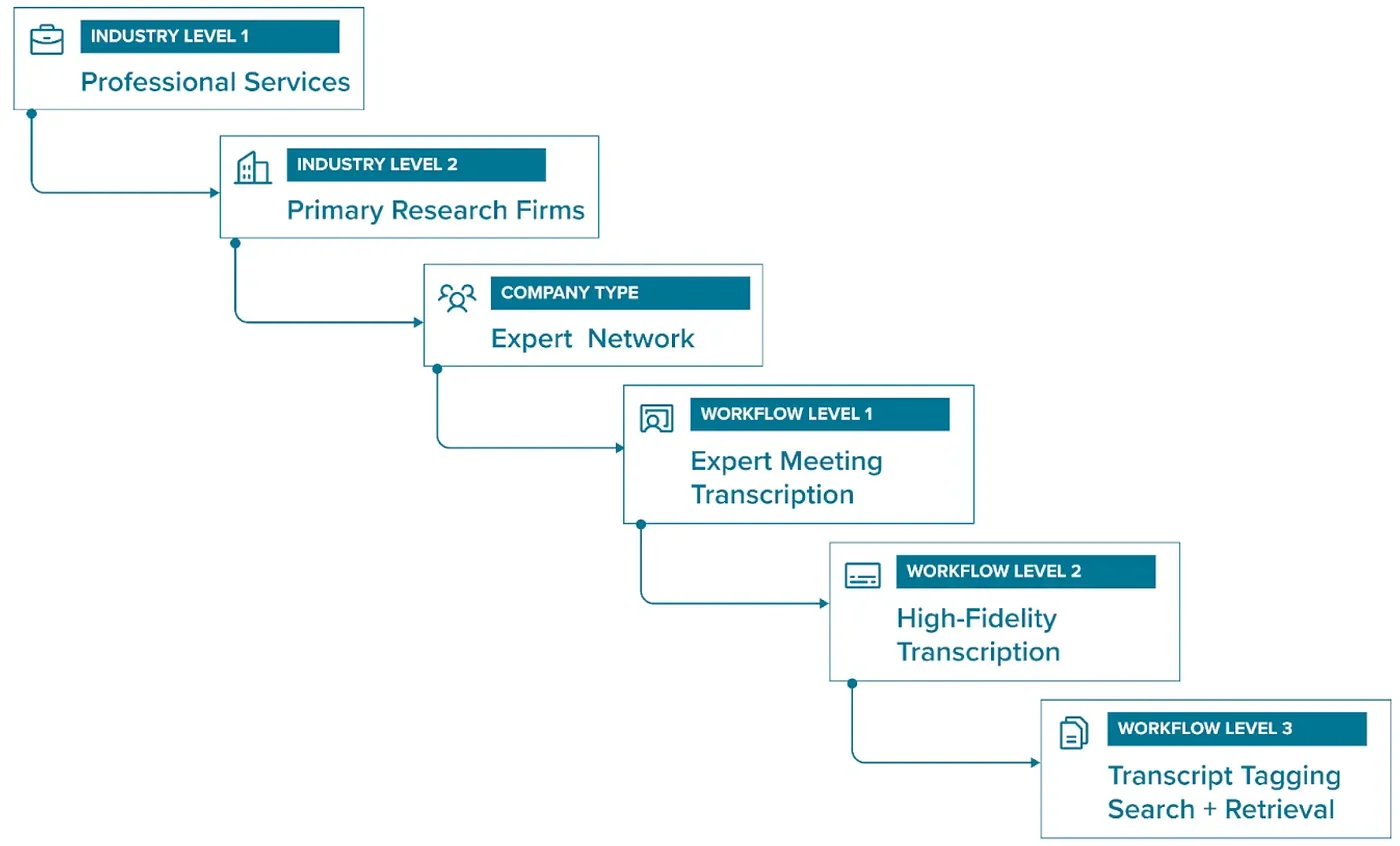
Expert networks are professional services firms that are increasingly diversifying their business model to include online platforms to complement their core expert call business, usually one-on-one research consultations. The CEO of an oil and gas company, for example, may want to conduct primary research about a particular geographic region prior to purchasing a company in that region.
Through an expert network service, the CEO can find and interview a professional with relevant expertise to interview on the topic. The audio of the conversation is recorded, transcribed into text, then provided to the client. From there, expert networks compile all transcribed interviews into an online web-based library, which is accessible with a paid subscription. The more seamlessly end users can navigate this library of transcripts, the more valuable it is.
How entity and thematic tagging fits into the wider industry
Challenges
Building a library of tens of thousands of interview transcripts and making them easily searchable is a significant challenge. Many expert networks offer full text search of their libraries, but searching with keywords alone can yield incomplete results. For example, the keyword “energy” might not include relevant results like “oil and gas” or “renewables.”
Beyond search capabilities, expert networks want to provide useful knowledge-linking functionality within the documents themselves. While many AI providers offer simple entity recognition (i.e., Named Entity Recognition or NER), enriching the transcripts with more robust information about the tagged entities by linking (also known as disambiguation) to a structured knowledge base is really where the added value lies. For example, instead of simple entity recognition where an AI model will say “yes, this is a company,” expert network clients also want to know “which unique company is it, and what other information can you tell me about it?” This is where linking to a knowledge base comes into play.
Solution
Following is how the Kensho team envisions our tools being implemented for this use case:
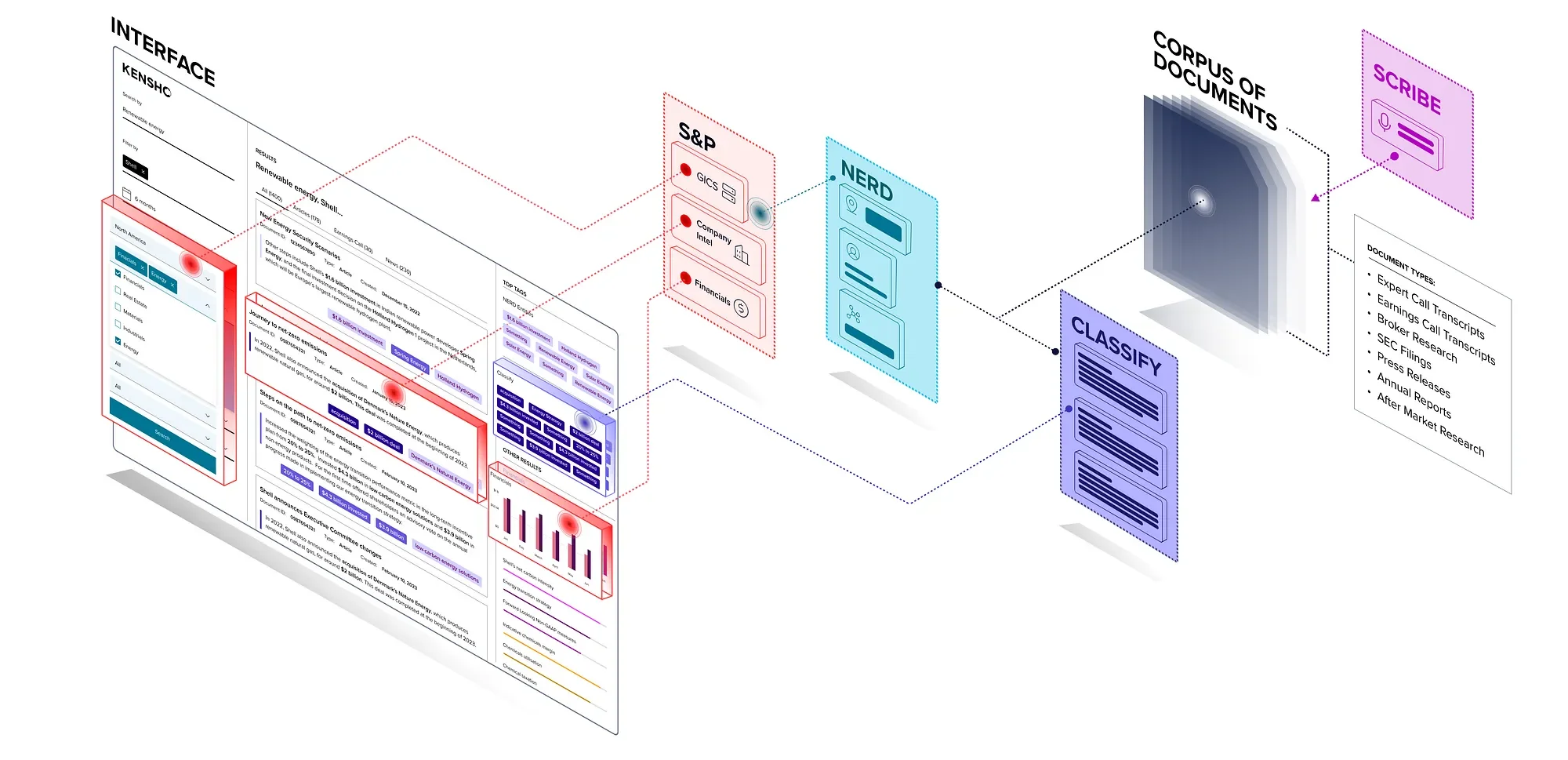
In addition to offering free text search capabilities for document libraries, Kensho layers in natural language processing (NLP) capabilities like entity and thematic tagging. Kensho NERD can identify entities in documents and text (named entity recognition [NER]), such as company names, but then, critically, also connects them to structured company profiles in S&P’s Capital IQ knowledge base (named entity disambiguation [NED]).
For example, using context clues, NERD can recognize an entity referred to in a document as “Exxon” as Exxon Mobil Corporation then pull in related data points such as the company’s market capitalization, geography, executive leadership and industry. The layering in of structured data sources available through S&P Global is a value proposition unique to Kensho and allows for more fine-tuned document filtering and insight gathering far beyond the capability of simply keyword or basic entity search.
Expert network companies can provide more powerful search capabilities using Kensho Classify, which identifies custom concepts in text. Instead of looking for keywords like “energy” or “oil,” Classify can analyze text at the sentence, paragraph or document section level to identify themes. For instance, a paragraph discussing economic headwinds could be tagged as “recession” even if that word is not explicitly mentioned. The complementary pairing of more specific word-level tagging offered by NERD with broader text-span tagging offered by Classify enables rich interconnections between specific companies and broad themes.
Imagine, for instance, that a private equity firm wants to look through an expert network library to find discussions about small- to medium-sized regional banks in the Midwest. This wouldn’t be possible with free text search alone. Kensho’s entity and thematic tagging, though, enables far more granular filtering (by industry, region, date, type of filing, etc.) through an easy-to-use interface, while also bringing in relevant S&P Global data.
Kensho increases the value of transcript libraries by allowing end users to find the information they need quickly and easily.