
Enhanced document extraction for generative AI use cases
Kensho open-sources Kenverters — Python tools that make it simple to plug Kensho Extract directly into RAG pipelines, LLM workflows, and table extraction applications.

Kensho Extract is known for its innovative features, including first-class text ordering and recently released state-of-the-art table structure recognition. As Extract’s features continue to expand into more sophisticated document segments, the richness of its output will only grow. With the newly released Kenverters, you can have the best of all worlds: the power of granular, hierarchical relationships without the complexities of manually parsing a tree structure. Integrating Extract into your Generative AI (GenAI) and document processing pipelines has never been easier.
RAG/GenAI
Are you using documents as input to your RAG or LLM use cases? Kensho Extract is an essential first step in this workflow, parsing documents into a well-structured, machine readable format. With Extract and Kenverters, you can easily parse your PDF documents and convert the output into AI-ready formats such as pandas DataFrames and markdown. Extract’s preservation of natural reading order can greatly aid an LLM’s context or create more coherent chunks for a vector database. Kenverters easily parses Extract’s intricate JSON structure into pure text or markdown. It can also return sections or pages of your document and their titles in order to more intelligently chunk your documents and keep relevant information together. Various table formatting options allow for a customized output that best suits your model.
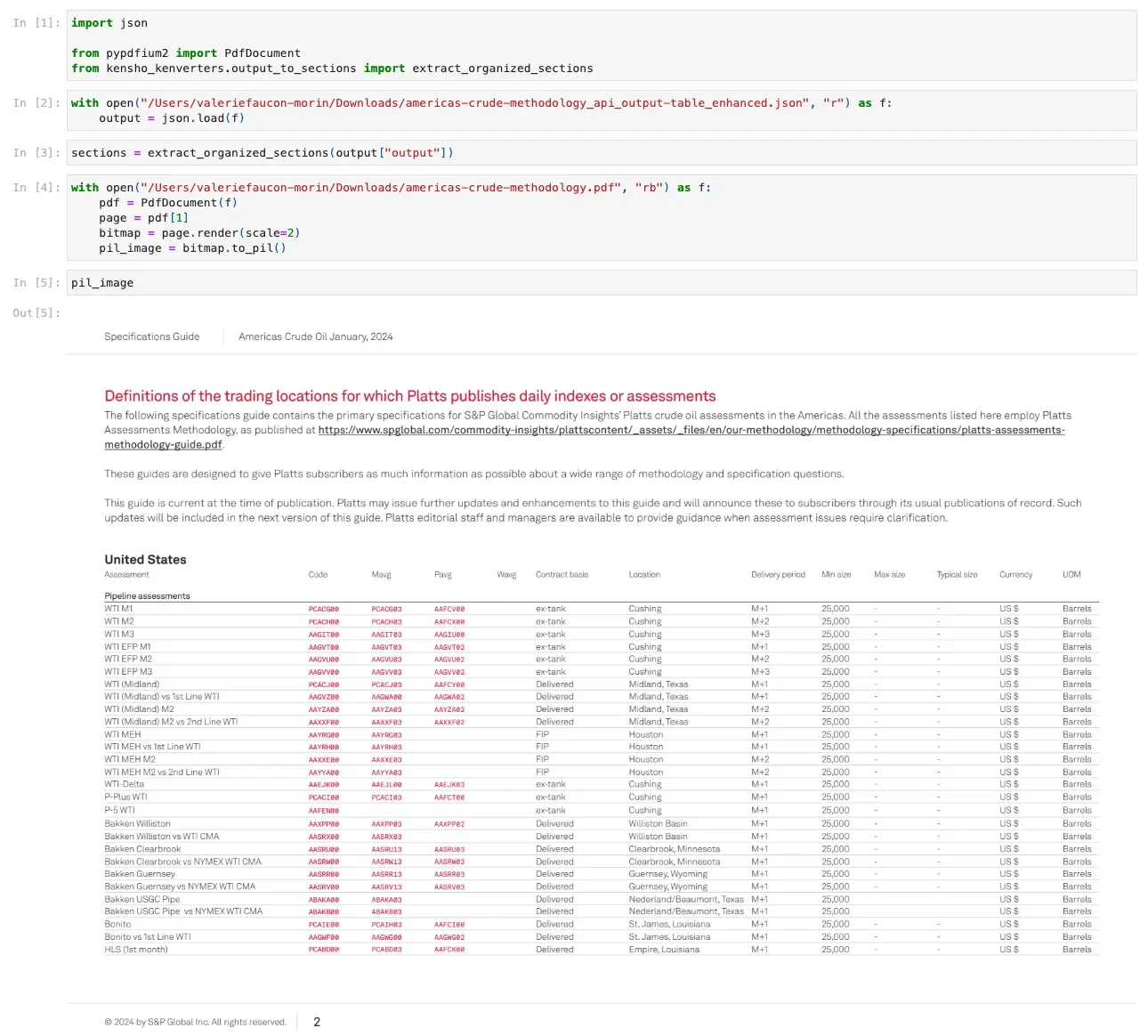
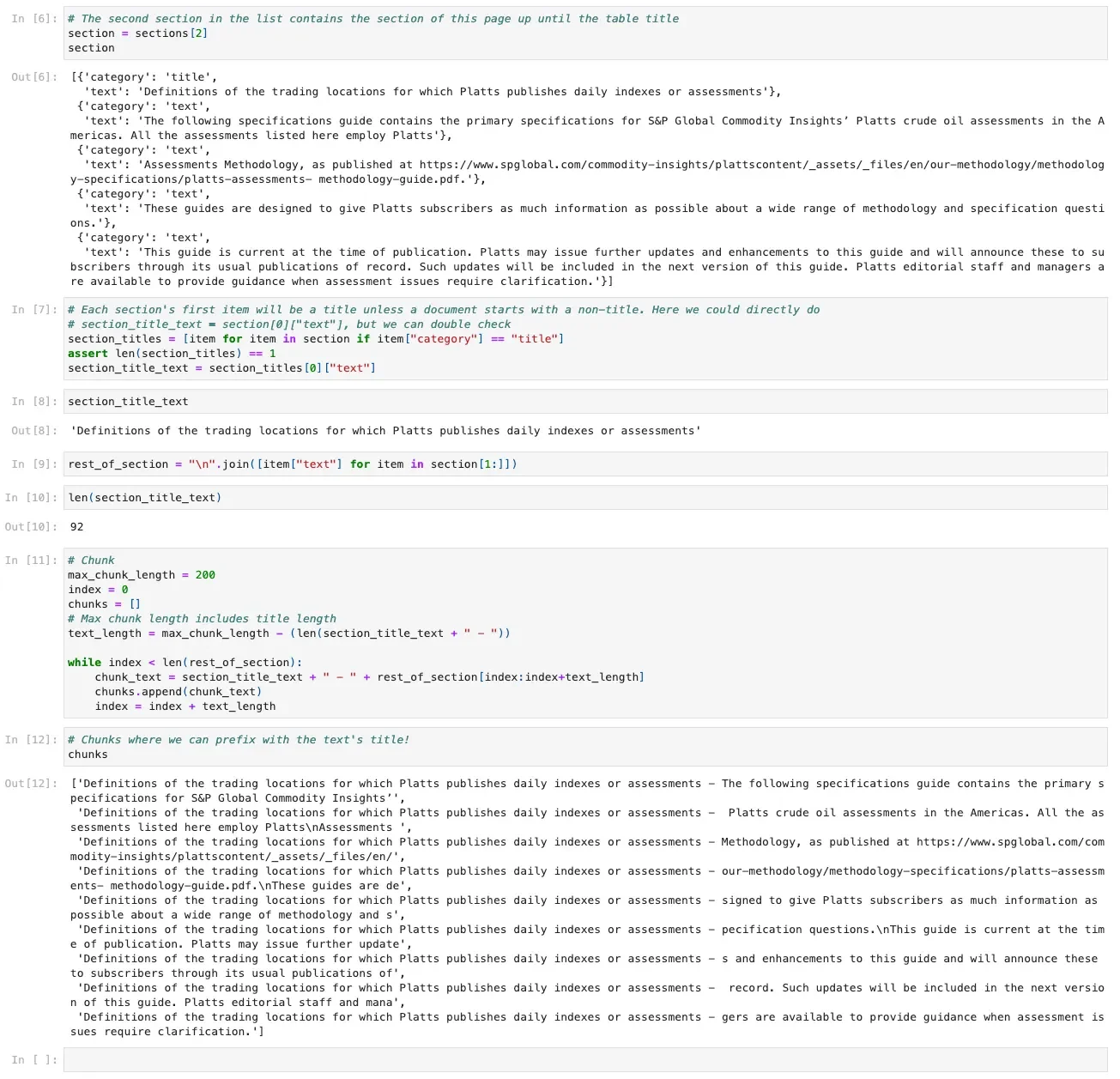
Example of Kensho Extract’s chunking output
Before Kenverters, separating Extract’s output into sections required 261 lines of code:

Code required prior to using Kenverters
Today, all you need is one import and you’re ready to go!

Image of Kenverter tool
Exporting tables
One simple function call can now take your full document’s Extract output and return all the tables in natural reading order and in a variety of common formats. For further downstream processing in Python or easy export to CSV, you can use Pandas DataFrames. The state-of-the-art table structure recognition model shines when parsing complex tables involving multi-row column headers and spanning cells. Additionally, Extract and Kenverters preserves all of this rich structural information and makes it programmatically available in easy-to-use formats.
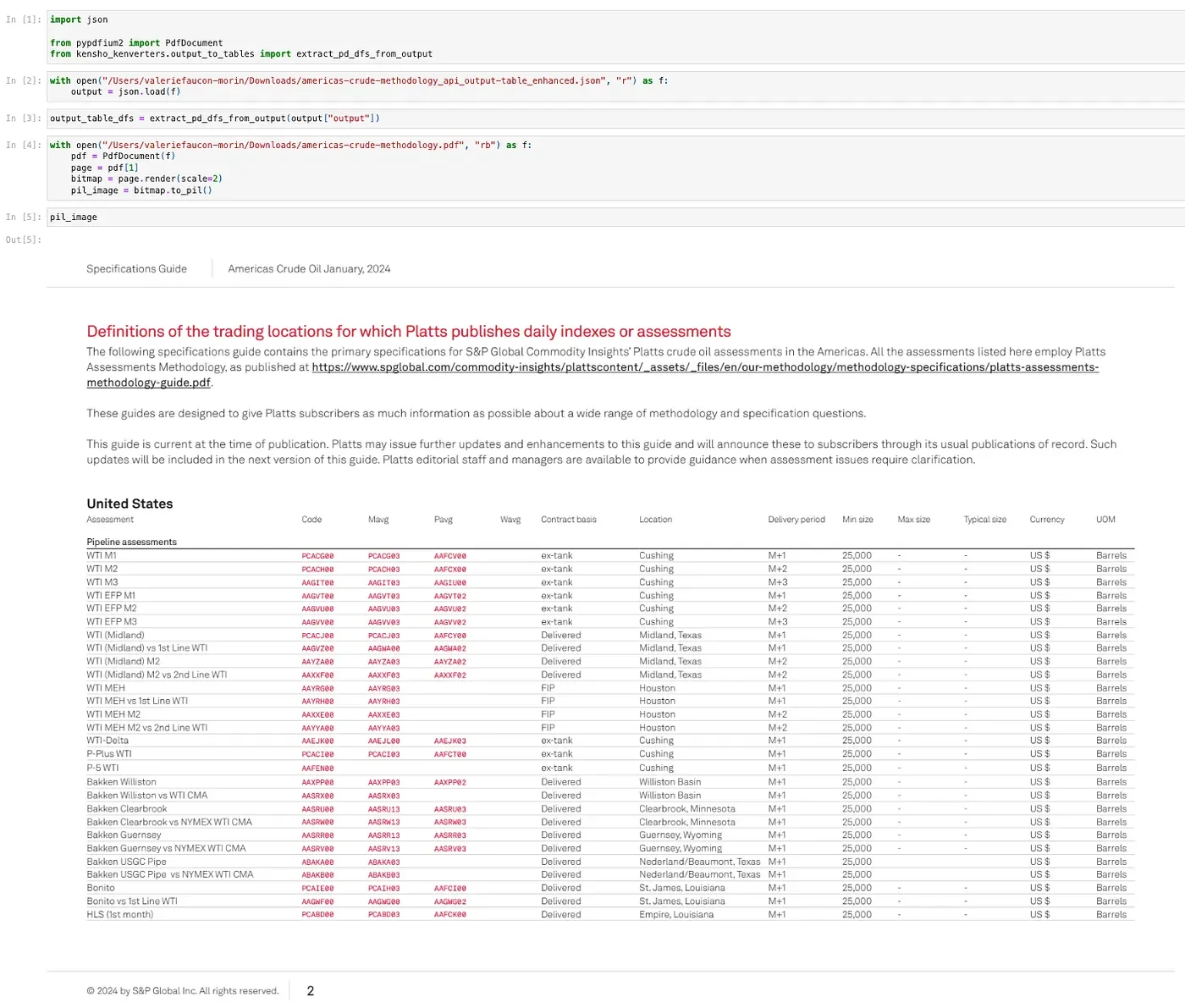
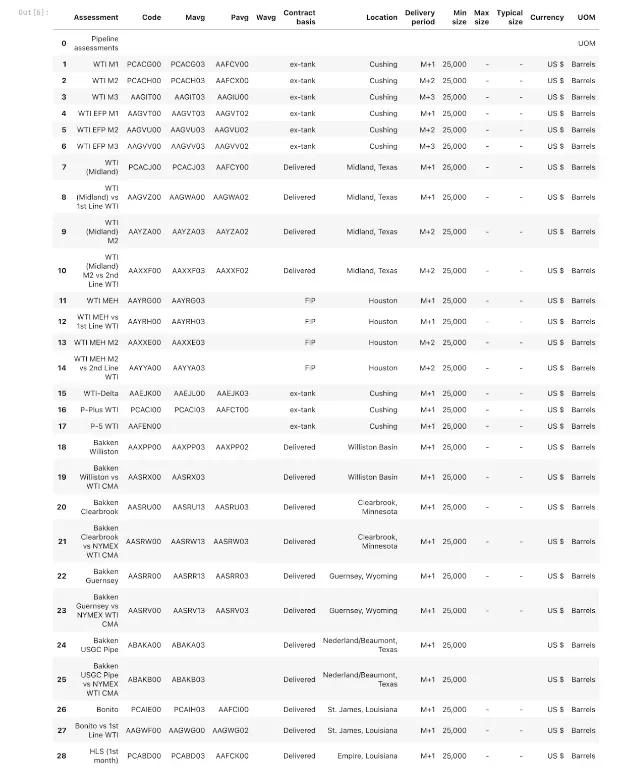
Kensho Extract’s table export function
Kensho Extract’s table export function
Visualization
Today, developers working on visualization use cases have to write their own converters from scratch. A useful new feature we recently included as part of Extract’s enriched output is “structured_document_with_locations” (https://docs.kensho.com/extract/quickstart). All Kenverters functions come with a counterpart that returns results with locations, automating the visualization process and enhancing user-friendliness. Using this function to call the Extract API lets you keep text, their associated page, and bounding box locations together. Kenverters also allow you to represent the original document in plaintext with the same visual formatting as the original PDF.
Try Kenverters today!
Kenvertersis Kensho Extract’s open source tooling to power your downstream use cases with ease. Using Extract’s rich features is now uniquely user friendly, leading the market in developer experience. Read our docs and try it out today!