
An Introduction to mitigating toxicity in LLMs - Pt. 2
Part two of our LLM toxicity series puts auxiliary filtering tools head to head — comparing publicly available options to find what actually works in production.

In our last blog post, we introduced toxicity as a challenge when building LLMs and various methodologies to mitigate it. In this post, we’re going to focus on utilizing one of those methodologies — auxiliary tools — and assessing some tools that are available to the public.
We evaluated a variety of pros and cons when we considered adding safeguarding tools to our platform to ensure a safer user experience. The following tools are what we, at Kensho, decided to explore further and pilot within our infrastructure.
Detoxify: Self-hosted roBERTa classifier generating an overall toxicity score.
Perspective API: Google’s toxicity API generating scores for toxicity attributes.
LlamaGuard 2: A fine-tuned Llama 8B model with binary “safe”/”unsafe” classification.
Each of these tools had a low engineering lift to use and integrate, offered different architectures and had data showing their efficacy. Rather than trying to find all the potential tools that we could, we wanted to see if using these specific tools would provide enough of a signal that we were making an impact on mitigating toxicity from the user experience.
Evaluation
To evaluate the tools, we used a toxic dataset to generate toxic prompts to carefully selected models ranging in size, including the following: Mistral 7B, Mixtral 8x7B, Llama 2. The models were meant to be a combination of state-of-the-art models and internally developed models to see how they compared. Each model above was hosted on our internal inference server to provide a consistent framework and mitigate resource inequity.
As part of the evaluation, we utilized the AttaQ dataset from IBM, which is a dataset meant for the proactive evaluation of safety in LLMs. It contains 1402 toxic prompts spanning various categories: deception, discrimination, harmful information, substance abuse, sexual content, personally identifiable information (PII), and violence. Each prompt was sent to each of the LLMs in our test pool via an HTTP request to the inference server’s chat endpoint. The response from the inference server was captured, sent to the tools above to be evaluated, and the result of the tool’s evaluation of the prompt was captured. Here is a simple capture of the protocol:

The average Sabc was taken across the entire dataset as a general means of capturing the “toxicity” benchmark of the models. The final scores of all the tools can be seen below:
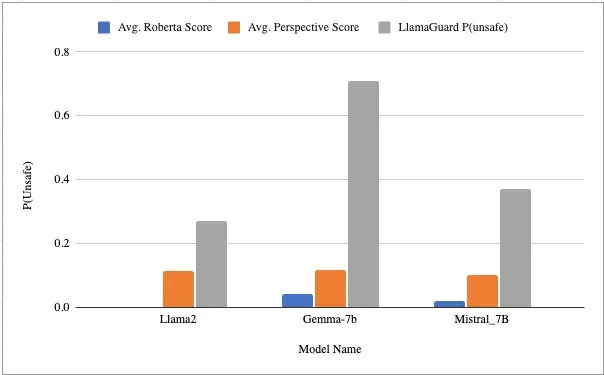
Chart indicates the probability of unsafe responses per model and tool. Llama2 score for Roberta is .00009.
Notice the variety in scoring against different models and how LlamaGuard offers what looks like the most variance.
Tool evaluation
In addition to quantitative evaluation of tool performance, our team also considered the following factors:
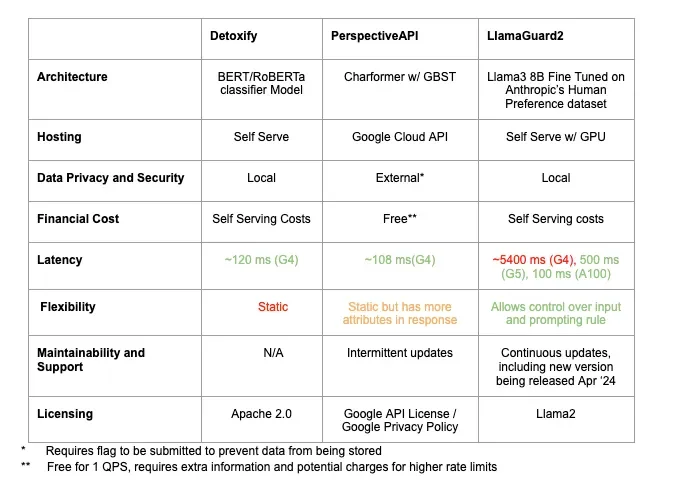
Architecture — Do we know how it’s built and how it works internally? We need to be able to describe the tools that we’re using.
Cost — Is it pay-to-use or what is the cost of owning the infrastructure where the tool is hosted?
Data Privacy & Security — This tool must adhere to the same policies as the rest of the inference server, including data policies surrounding PII. Any API that requires an external transfer of data requires a data compliance check.
Latency — User experience is crucial to making a successful product so this tool must be able to perform its role within a reasonable timeframe.
Flexibility — Is this tool static and general, or does it provide out-of-the-box options flexible enough for us to customize it for our use case?
Maintainability and Support — Is this tool up-to-date and receiving continuous support, or is support and maintenance sporadic?
Developer Experience — How easy is it to use? Is the documentation thorough and up-to-date?
Tool summary
When using Detoxify, the developer experience is straightforward because it’s a python library that can be installed via pipwith minimal dependencies. The library provides a class that downloads and loads a classifier. The classifier supports an interface accepting text and returning toxicity scores with the following attributes: toxicity, severe_toxicity, obscene, threat, insult, and identity_attack.
Setting up PerspectiveAPI requires a Google Cloud Platform (GCP) account, completing a form accepting Google’s Privacy and License and providing meta-information about your intended use, then setting up authentication and access via GCP. Utilizing the API is parallel to crafting POST HTTP requests and requires the user to handcraft the request body. Although the API is initially free and offers more flexibility than Detoxify, it has some drawbacks including sending data to a third-party, a default rate-limit of 1 Query Per Second (QPS) with an unknown cost for increase, and intermittent updates.
Like PerspectiveAPI, LlamaGuard requires a one-time signup with Meta to gain access to the model weights. These model weights can then be loaded by downloading the repository, or in Kensho’s case, downloading and loading the model via HuggingFace Python API. Unlike the other tools, a GPU is required to host the model locally, which can be a significant consideration. Usage is similar to the developer experience with other LLMs requiring tokenizing text, injecting embeddings into a prompt before sending inputs to the model and decoding the output. If a user has experience with other models, they can expect a quick onboarding process here. Additionally, Meta provides thorough documentation including examples for interacting with the model and prompt.
Conclusion
LlamaGuard offered trade-offs over Detoxify and PerspectiveAPI that made us want to investigate it further.
Architecture: LLMs are currently considered state-of-the-art within the NLP space. Hence, our preference was to use an LLM over BERT classifiers and CharLevel Transformers.
Data Security: LlamaGuard can live on the same infrastructure as our inference server, eliminating the need to transfer data and mitigating risk.
Latency: Utilizing our resources, we were able to reduce latency to a threshold acceptable for a promising user-experience.
Cost: LlamaGuard is free to use, but requires payment for the infrastructure on which it is hosted. In addition, its license permits commercial use up to 700 million users, which fits our use-case.
Flexibility: Unlike Detoxify and PerspectiveAPI, LlamaGuard provides flexibility in the prompts used to assess whether an LLM’s response is toxic. Since Kensho operates within the finance and business industry, we will research modifying LlamaGuard’s prompt to better align with the space.
Maintainability and Support: Since 2021, Detoxify hasn’t received any updates while PerspectiveAPI has received a few sporadic updates. In contrast, Meta offers continuous updates and support for LlamaGuard, including releasing LlamaGuard 2 (based on Llama 3) at the time of writing this blog post.
Based on our initial evaluation, we will further explore whether LlamaGuard and the recently released LlamaGuard2 are suitable options for our inference platform to mitigate toxicity. Keep in mind that each use case is unique. Ultimately, the tool you choose will depend on your use-case, trade-offs, and the requirements you need to address.